Creating an AI to play Slay the Spire is not easy. The roguelite traits that give the game replay value also make it hard to craft a single policy to play the game: randomness, procedural map generation, card drafting, convertible currencies (health, gold, cards, etc.), long reward horizon, powerful but rare synergies between relics and cards, and so on.
I’ll go through my tribulations over the months I’ve worked on this (incomplete) project. I hope it’ll help others who also want to create a Slay the Spire AI.
Existing work
I only know of two existing AIs.
spirecomm
This is, as far as I can tell, a demo for the mod that it’s packaged in. It uses hardcoded strategies and priorities. In my opinion, this approach won’t scale to playing at a high level.
STS Battle AI
This is a combat only AI that uses a purpose-built mod to run A* search on the game decision tree as it’s played. It plays far better than any AI I’ve trained, although I’ll note that the “save scum” approach it uses to create a game decision tree exploits hidden game internals like RNG seed–it can see the future.
Approach
I chose model-free reinforcement learning (RL). RL seems a natural choice when you can play a game many times.
Advantages
- Model-free RL doesn’t need to be told the game’s dynamics
- Ideally, the more it trains, the better it plays
- No need for a large number of game replays to learn from
- If you do have lots of game replays, you can use them to give the agent a head start (transfer learning)
Disadvantages
- On-policy RL is sample inefficient–it has to play the game a lot to get good
- May need lots of computation to train relative to other ideas like STS Battle AI’s game tree search
Implementation
I chose rllib because it supports action masking. I considered stable-baselines, but its action mask support was still in the works at the time. I’ve used PPO and A2C trainers.
Attempt 0: Training at human speed
I hooked up rllib up to the actual game via spirecomm with no other modifications. It played at human speed with graphics. This did not work.
Lessons Learned
Create a way to play the game fast. I started work on decapitate-the-spire, a headless python clone of the game.
Attempt 1: RL is magic, right?
I got overhyped on RL after hearing it learned to play Atari games from raw pixels. I thought I could toss the game at any RL trainer with no thought and get a good agent. This did not work.
Among other problems, the action space I developed was probably too complicated. The part that represented playing cards in combat was essentially <card in hand index> × <target index>. For example, (4, 1) would translate to “play card in hand at index 4 against the monster at index 1:
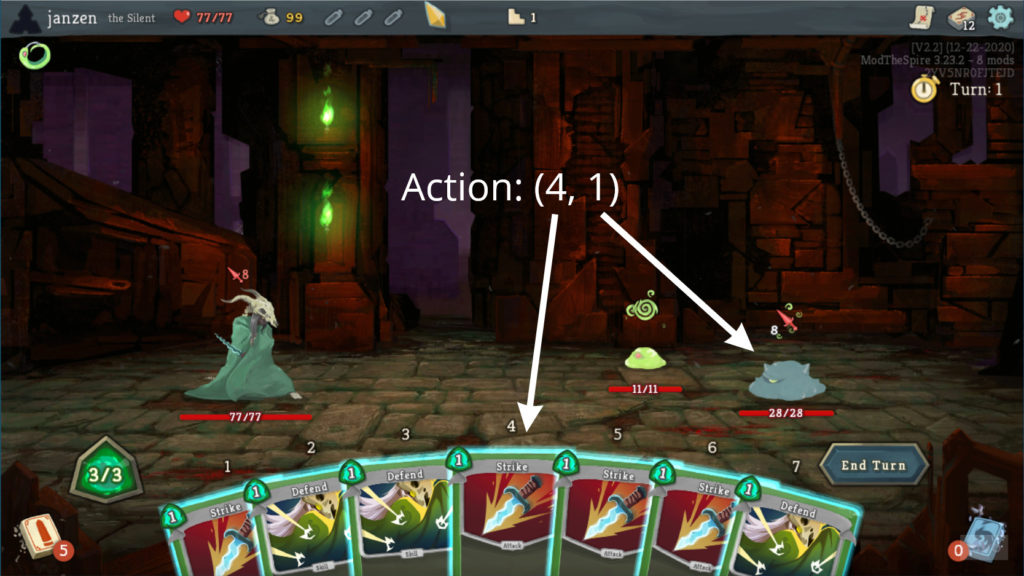
Note that there’s no mention of a specific card type in that translation. I suspect this action space wasn’t good because there was indirection between “card in hand index” and the effect that playing that card had.
What I mean by that is, it’s hard for an agent to learn that playing “card in hand at index 4” only does 6 damage to a monster when the environment indicates that the card at index 4 is Strike. It’s much simpler if “pressing a button” always the same effect.
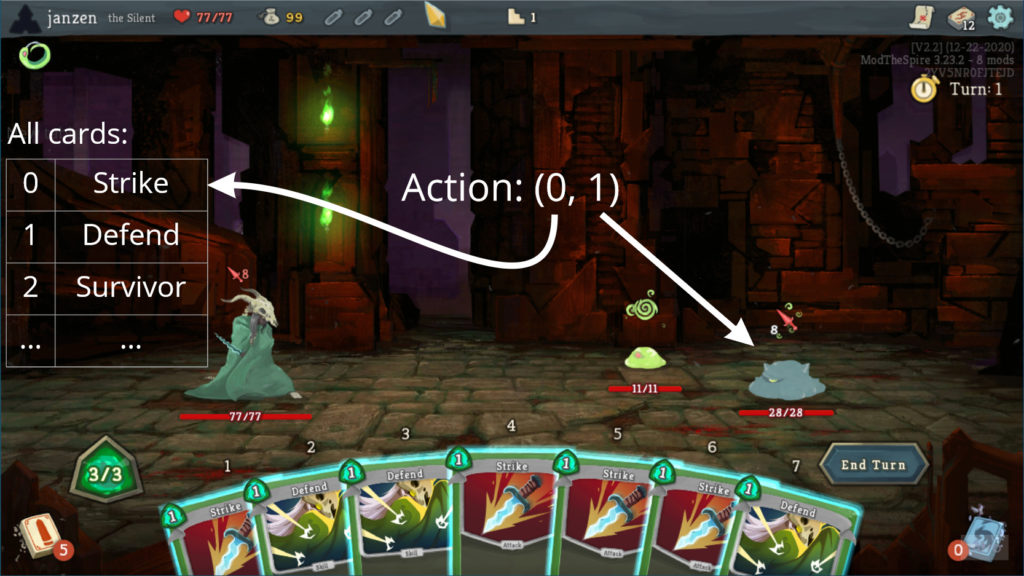
The learning environment at this point was the first dungeon of the game–Exordium. A dungeon is a series of about 15 encounters that could be combat, shops, events, or treasure, and ends with a boss combat. I rewarded the agent for completing encounters and punished it for dying. These episodes were too long and the rewards too sparse.
Lessons Learned
Break the problem down into achievable milestones
It’s very hard to tell if your agent is progressing or how long it needs to train when you have no known good foundation to build on.
Reward the agent frequently
If you’re wearing a blindfold and trying to reach a door, it’s much easier if someone gives you feedback like, “warm, warmer, cool, cool, warm.”
Redesign the action space
The agent wasn’t going to learn to play the full game magically. I didn’t mention this above, but the action space was overloaded to cover the entire game: combat, shops, events, rewards. So an action that means “play the second card against the first monster” during combat might mean “buy the second relic” at a shop. I thought compressing the action space was good, but I doubt that now.
Attempt 2: Half measures
I applied some of the lessons learned but didn’t see success. Shorter dungeons, making combat easier, more frequent rewards–none of it made much difference.
I walked away from the project for a couple months here. I came back with a new approach.
Lessons Learned
Reward engineering is not as easy as it seems
Once, I added a small punishment at each time step to encourage the agent to play faster (who needs a discount factor?). The agent converged quickly. Its strategy was to die as quickly as possible.
Attempt 3: Hit the books
I realized I couldn’t bash my head against the problem and hope for a solution to fall out. I read papers, watched David Silver’s lectures, and drastically simplified the game.
Autoregressive actions
I learned about autoregressive actions from the SC2LE paper. Autoregressive means that the actions are aware of what came before. For example, part of an autoregressive action space for this game might look like:
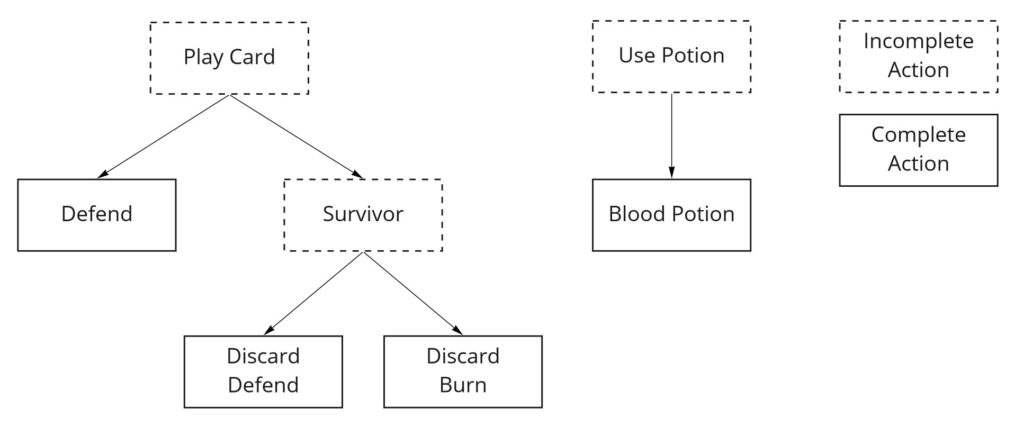
On the first pass through the model, it would decide whether to play a card, use a potion, etc. If it chose to play a card, you’d take another pass through the model to decide which card to play. If the action is complete (i.e., the card is simple like Defend), then the action is sent to the game.
If the action is not complete because, for example, the model chose to play Survivor, which requires the player to discard a card, then you take another pass through the model to choose which card to discard.
During each model pass, the model knows which partial actions it’s already chosen. That’s what makes the actions autoregressive. This is not the same as the model knowing any previous complete actions it chose.
This approach feels much more natural than the generic action space I first used, where each point in action space had several semantic meanings depending on the “request type”.
Simplifying the game
I couldn’t tell whether the agent was playing better as it trained. So, I simplified the game by reducing it to a single toy combat instance. I made the game simple enough that I, a lowly human, could figure out the optimal policy and see if the agent found it, too. A small, achievable goal.
The first, simplest game variation I made had an empty observation space and two actions. Picking action 1 rewarded the agent and ended the game. Picking action 2 punished the agent and ended the game. This game is one step above trivial, but it gave me a baseline for how much training the agent needed to find the optimal policy.
The second game variation added a boolean observation that determined whether it was action 1 or 2 that rewarded, and the other punished. This showed that the agent could act based on observation. Again, very simple.
The third game variation added a feature that was random noise to the observation, showing that the agent could learn to ignore useless information.
And so on.
Current status
I’m focusing on creating an agent that only plays combat for now. This goal is more approachable and progress is easier to measure than a full game agent.
Future work
Composite agent
I’m not sure that using a single agent to play the entire game is the best approach. One idea I’ve had is to use multiple agents that each handle a different aspect of the game: combat, card drafting, shop purchasing, events. A single “orchestrator” agent could make map selections and let its subordinates handle that map node.
I’m not sure how training for this would work. I’ve imagined freezing all the agents but one and training that one for a while on the full game, then rotating.
The biggest problem I see is how to push long term strategy down to the subordinate agents. I’ve seen that existing agents can be short sighted–they love using consumables like potions, which is great now but maybe not strategically best.
To fix this, I imagine the orchestrator agent providing its subordinate agents with some distillation of information like “We’re facing Bronze Automaton at the end of this dungeon, so please avoid using this Ghost in a Jar potion unless you’re really in trouble”. This could be as simple as a number between 0 and 1 indicating how much trouble the subordinate needs to be in before it uses consumables.
I go back and forth on this one. I’m not sure whether this would really be better than training a single agent on the full game.
Per-encounter combat agent
The idea here is that it must be easier to learn to play a single encounter than to play generally against all encounters. Different monsters in different encounters require different approaches. For instance, the agent should play with much more haste against Reptomancer than Giant Head.
The advantage is that (I would imagine) it’s much cheaper in time and resources to train a competent agent for a single encounter than all encounters. This would tighten my development feedback loop, which is very good.
Of course, there are disadvantages as well. There will be some core knowledge that all agents will learn: that Headbutt puts a selected card on top of draw pile, that Apparition is a very good card, etc. I’m getting a headache imagining the infrastructure I’d need to build to train agents for all encounters.
Transfer learning
I would love to seed my agent with expert play. Unfortunately, as far as I know, there’s no replay system for the game. Save files are not sufficient because they only encode the game’s current state. I’ve considered writing a mod that records comprehensive replays and asking expert players to use it, but that’s a whole new project.
I’ve also considered creating something that can reconstruct replays from videos of gameplay, because there are plenty of those on YouTube. But again, that’s a whole new project.
Assist mod for actual game
I think the agent could power an assist mod that gives human players in-game information to improve their play. These wouldn’t need to exploit hidden game internals to be useful.
Deck analysis
With a combat playing agent, I could generate data to train a model that predicts the player’s HP loss for a given single combat. HP is probably the most important game currency. This model should depend mostly on relics and card deck.
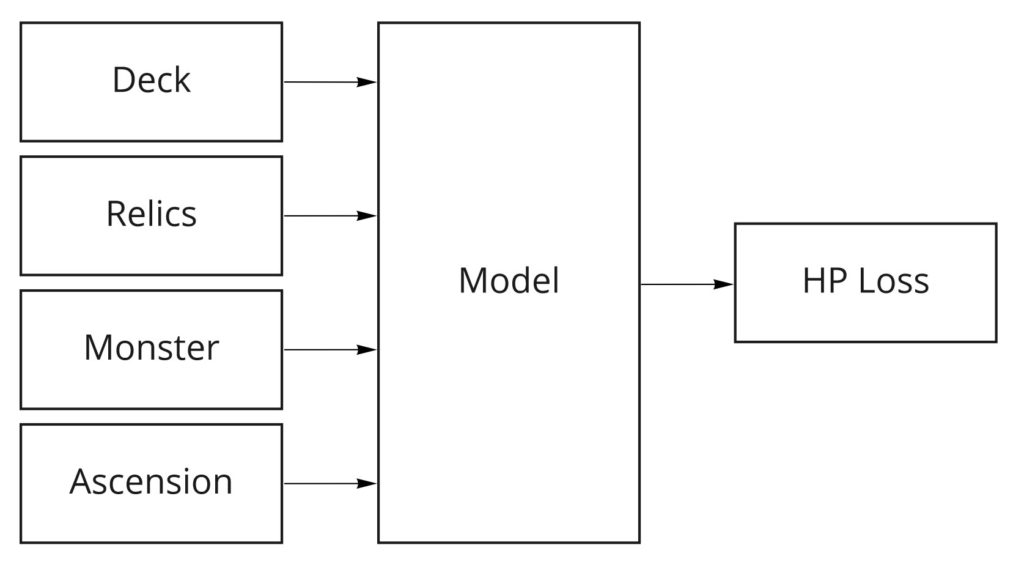
My hope is that I could reduce the dimensionality of the model input so that instead of considering an explicit representation of relics and card deck, it considers a few numbers. In my dream, these numbers would end up representing established game concepts like “single target scaling damage” and “card manipulation”.
These numbers would be useful to show the player when they’re drafting cards. Showing that the player already has high “multiple target scaling damage” but low “single target upfront damage” could lead them to draft Backstab over Noxious Fumes. A simple mockup:
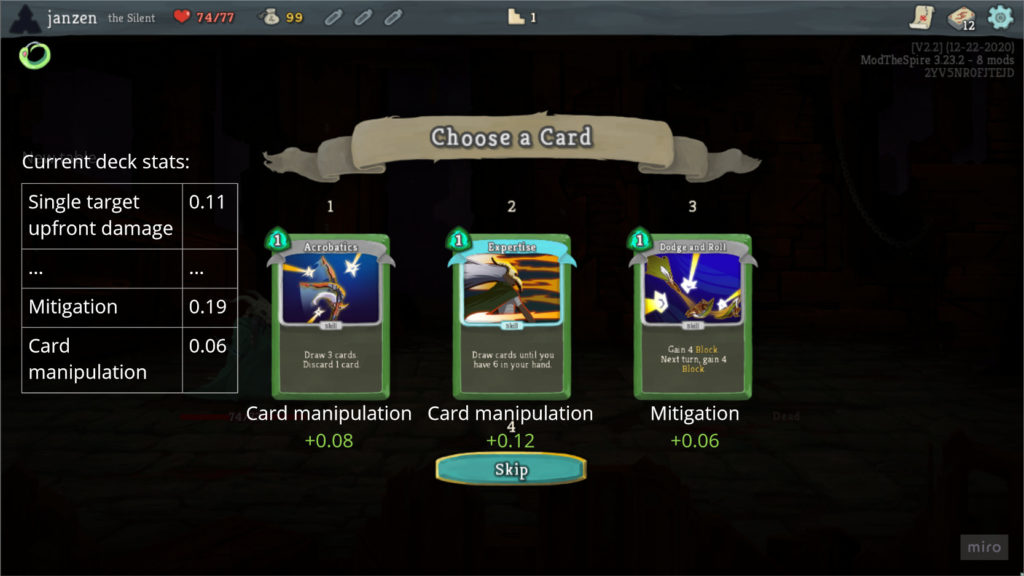
This might also have applications for training an agent to draft cards.
Map annotation
It’s very important to pick a good path through a dungeon’s map. There’s a “push your luck” mechanism here. You want to fight tough monsters to get better cards and relics, but leave yourself enough health, potions, etc. to survive the boss fight at the end of the dungeon.
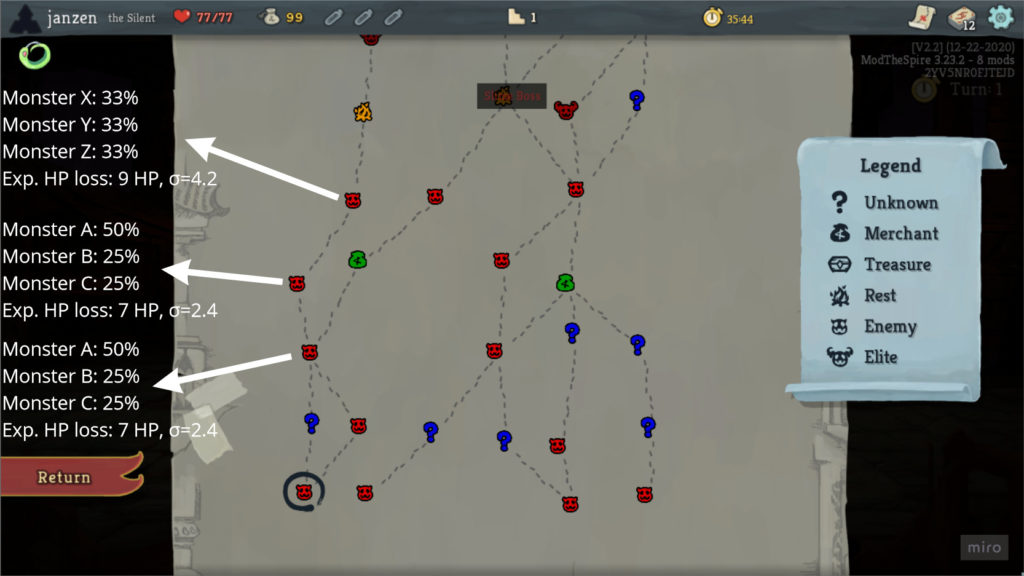
Using the aforementioned model that predicts HP loss, I think it would be useful to annotate the map with expected HP loss and variance for each monster map node. The distribution of monsters per dungeon is not a secret (i.e., it’s not generated per game based on a random seed, although the actual monsters sampled from the distribution is), so I don’t consider this cheating.
Evaluation gauntlet
To help me evaluate the performance of agents, I could construct a gauntlet of puzzles that each have a clear answer.
For example, I could drop the agent into a combat where the monster is attacking for 11 and has 7 HP. The player’s hand contains four Defends and one Strike. The draw pile is two Strikes.
A novice player might play the single Strike in hand because damaging monsters is a pretty good strategy. The monster is still alive with 1 HP, though. The player has only two energy left to play two Defends, which only blocks for 10 against the monster’s attack for 11, so the player loses 1 HP.
Because the player can’t kill the monster this turn but is guaranteed to be able to do so next turn, the optimal choice is actually to play three Defends this turn and two Strikes next turn, which wins the battle with no player HP loss.